SQL
SQL staat voor Structured Query Language. Het is een taal om informatie in en uit databases te halen. Een database is te vergelijken met een spreadsheet (omdat spreadsheets eigenlijk gebaseerd zijn op databases). Het is een collectie tabellen. Een tabel heeft kolommen, zoals “Naam”, “Email”, “Geboortedatum”, “Bio” etc. en rijen.
De rijen noem je soms entities of results. De kolommen noem je soms keys of velden.
Opbouw van een query
SQL code noem je een query (opvraag). De meest simpele query is:
SELECT * FROM `employees`;
Er zijn hier een aantal dingen:
-
Keywords zoals
SELECTenFROMvertellen de computer wat hij moet doen. Deze schrijven we met hoofdletters. (Technisch gezien zijn de hoofdletters optioneel, maar sommige oude systemen werken niet met kleine letters en hoofdletters zorgen ervoor dat je duidelijk kan zien dat het keywords zijn.) -
Verwijzingen naar kolommen, tabellen of variabelen zetten we in backticks (`). Dit is technisch gezien ook optioneel, maar soms krijg je hele rare errors als je het niet doet. (Het doet ook iets met het voorkomen van SQL injection attacks maar ik ben vergeten wat ook alweer.)
-
Een query eindigt altijd met een puntkomma (;).
Je mag een query ook over meerdere regels splitsen. Dit is vooral handig bij hele lange queries:
SELECT *
FROM `employees`;
SELECT: velden ophalen
Om informatie uit een database te halen moet je eerst kiezen welke velden je wil zien. Het meest simpele voorbeeld zag je hiervoor al.
We selecteren daar alles (* is een joker) uit de tabel “employees”. We kunnen ook iets specifieker dingen ophalen:
SELECT `first_name`, `hire_date` FROM `employees`;
Je scheidt de velden die je wil ophalen met een komma.
LIMIT: maximale hoeveelheid rijen
Met LIMIT kan je opgeven hoeveel rijen je maximaal wil ophalen:
SELECT * FROM `employees` LIMIT 3;
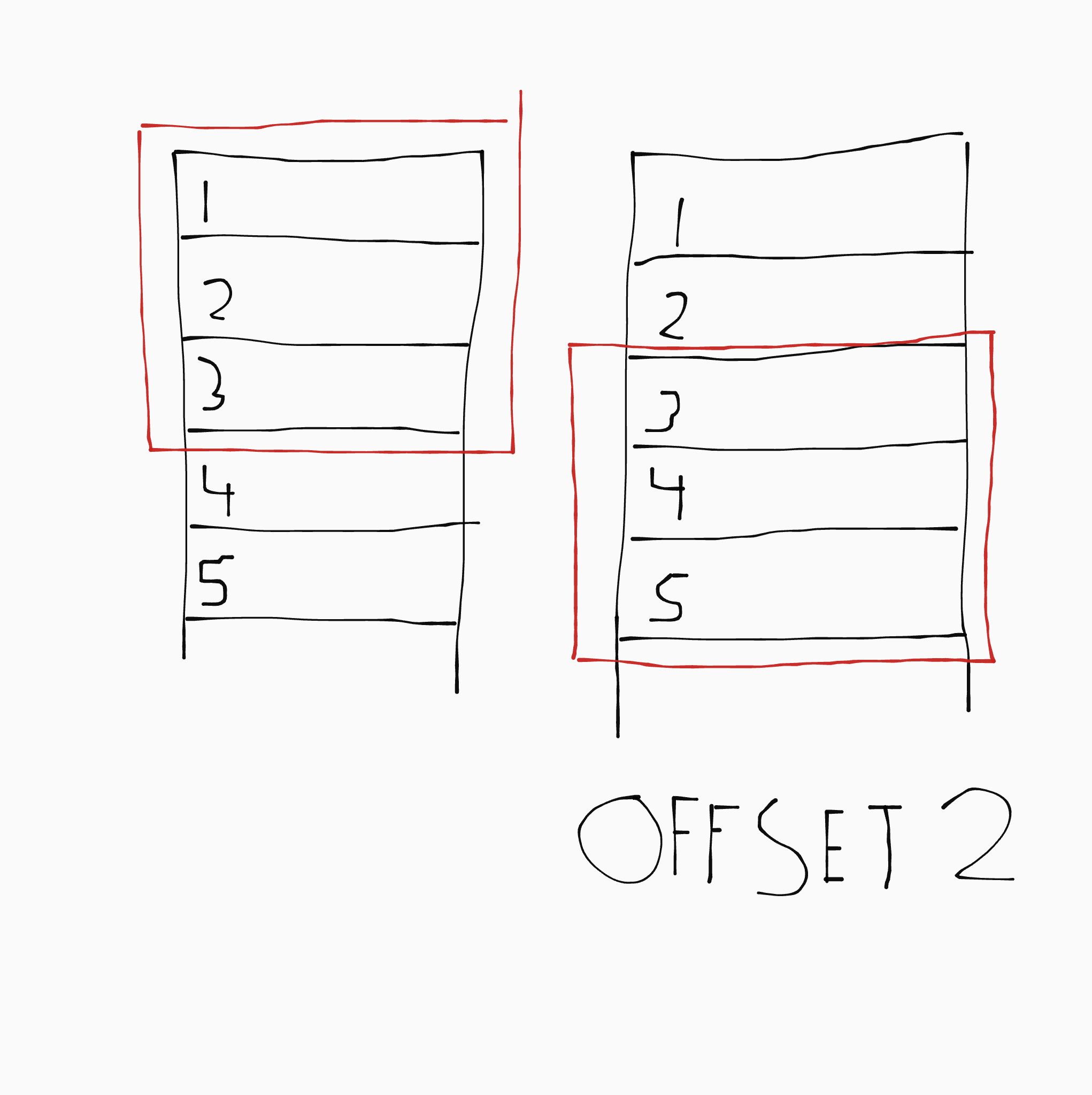
Het vorige voorbeeld haalt de bovenste drie rijen op. Je kan met LIMIT ook OFFSET gebruiken. Met OFFSET kan je rijen overslaan. Dit voorbeeld haalt de derde, vierde en vijfde rij vanaf boven op:
SELECT * FROM `employees` LIMIT 3 OFFSET 2;
Je kan het zien als een soort raam dat over de tabel schuift:
WHERE: informatie filteren
Met WHERE kan je alleen rijnen die aan een voorwaarde voldoen ophalen:
SELECT `first_name` FROM `employees` WHERE `salary` > 1000;
Dit zijn de meest simpele voorwaarden:
x = y # x same as y
x != y # x not same as y
x > y # x bigger than y
x >= y # x bigger or equal to y
x < y # x smaller than y
x <= y # x smaller or equal to y
Je kan voorwaarden ook combineren:
a AND b
c OR d
NULL
Als een kolom geen waarde bevat zie je NULL staan. NULL is dus eigenlijk het gebrek aan inhoud. Als je moet werken met de waarde NULL gebruik je IS (NOT):
x IS NULL
x IS NOT NULL
IS en IS NOT zijn dus alleen voor werken met NULL!!
Lijsten
Met IN kan je checken of een waarde zich in een lijst bevindt:
x IN ('Appel', 'Peer', 'Banaan')
Dit is kort voor:
x = 'Appel' OR x = 'Peer' OR x = 'Banaan'
BETWEEN
Met BETWEEN check je of een waarde tussen twee getallen ligt. Dit werkt dus alleen met getallen!
x BETWEEN y AND z
Dit is kort voor:
x > y AND x < z
DESCRIBE: structuur van de tabel bekijken
DESCRIBE laat de structuur van de tabel zien. Je hoeft deze niet te kennen voor de toets, maar voor de volledigheid is hier een voorbeeld:
DESCRIBE `employees`;
AS: variablen maken
Met AS kan je kolommen en berekeningen opslaan in een variabele. Een simpel voorbeeld:
SELECT `first_name` AS `name`, 12 * `salary` AS `year salary` FROM `employees`;
Je kan deze variabele pas hergebruiken na de SELECT. Dus dit kan niet:
SELECT 3 * `salary` AS `salaris kwartaal`, 4 * `salaris kwartaal` AS `jaarsalaris`
FROM `employees`;
# deze query is fout!
Maar dit wel (ORDER BY komt hierna):
SELECT 12 * `salary` AS `jaarsalaris`
FROM `employees`
ORDER BY `jaarsalaris`;
# deze query is wel goed :)
ORDER BY: sorteren
Je kan ORDER BY gebruiken om het resultaat van je query te sorteren:
SELECT * FROM `employees` SORT BY `salary`;
Het veld waarop je sorteert hoeft niet opgehaalt te worden in de query:
SELECT `first_name` FROM `employees` SORT BY `salary`;
# dit is een werkende query
Je kan bij sorteren ook een eerder berekende variable gebruiken, zoals je zag bij AS:
SELECT 12 * `salary` AS `jaarsalaris`
FROM `employees`
ORDER BY `jaarsalaris`;
Je kan op twee manieren sorteren: oplopend (ASC) en aflopend (DESC). Als je niet opgeeft of je ASC of DESC wil sorteren wordt DESC gebruikt.
Functies
Met functies kan je een waarde veranderen. Een functie is zoals een wiskundige functie: je gooit er iets in en hij poept iets uit.
ROUND,CEIL(omhoog),FLOOR(omlaag): shit afronden.UPPER,LOWER: maak dingen upper- of lowercase.-
SUBSTR: pak een gedeelte van een stuk tekst (string slice).SUBSTR('Robin', 1, 3) # dit wordt 'Rob' -
CONCAT: plak meerdere dingen aan elkaar.CONCAT(`first_name`, ' ', `last_name`) # Robin Boers CONCAT(LOWER(`first_name`), '@', `company`, '.nl') # robin@qdentity.nl -
YEAR,MONTH,DAY: haal een deel uit een datum.YEAR('2007-01-13') # 2007 MONTH('2007-01-13') # 01 DAY('2007-01-13') # 13 -
MONTHNAME,DAYNAME: haal een deel uit een datum, maar dan als fancy word :DMONTHNAME('2007-01-13') # January DAYNAME('2007-01-13') # Saturday (wauw ik ben op een zaterdag geboren cool) -
TIMESTAMPDIFF: rekent het verschil tussen twee data uit.TIMESTAMPDIFF(YEAR, '2007-01-13', '2008-03-16') # 1 TIMESTAMPDIFF(MONTH, '2007-01-13', '2008-03-16') # 2 TIMESTAMPDIFF(DAY, '2007-01-13', '2008-03-16') # 3 -
NOW: poept de huidige datum uit.TIMESTAMPDIFF(YEAR, '2007-01-13', NOW()) # 16
Grouping
In de queries hiervoor haalden we steeds een aantal rijen uit de database, en kozen we steeds hoe we ze wilden weergeven. “Plak de voor en achternaam aan elkaar”, “maak hier hoofdletter van”, “bereken een jaarsalaris” enz. Dat ging per rij. De queries hierna gaan over het samenvoegen van meederen rijen. Dat noemen we grouping.
Je hebt een aantal functies die rijen kunnen groeperen:
-
AVG: een gemiddelde uitrekenen van alle rijen.SELECT AVG(`salary`); -
MINandMAX: laat het grootste of kleinste van alle rijen zien.SELECT MIN(`salary`); SELECT MAX(`salary`); -
SUM: laat de som van alle rijen zien.SELECT SUM(`salary`); -
DISTINCT: laat elke waarde op een veld maar één keer zien.SELECT DISTINCT `job_title`;
GROUP BY
De functies hiervoor gooien alle rijen uit de tabel op één grote hoop. Met GROUP BY kan je bepalen dat ze groeperen per veld.
Neem bijvoorbeeld de volgende queries:
SELECT AVG(`salary`) FROM `employees`
SELECT AVG(`salary`) FROM `employees` GROUP BY `department_id`;
De bovenste query geeft één rij terug met daarin het gemiddelde salaris van alle werknemers. De onderste geeft per afdeling een rij met daarin het gemiddelde salaris van alle werknemers op die afdeling.
WHERE en HAVING
In het geval van grouping heb je twee belangrijke functies om mee te filteren. WHERE werkt, (net als normaal) op individuele rijen. Je kan hiermee bepalen of rijen wel of niet in de grouping worden meegeteld. Met HAVING kan je bepalen of groepen wel of niet worden weergegeven. Het is dus eigenlijk een WHERE voor groepen.
Neem bijvoorbeeld de volgende queries:
SELECT AVG(`salary`) FROM `employees` GROUP BY `department_id` WHERE `salary` > 1000
SELECT AVG(`salary`) FROM `employees` GROUP BY `department_id` HAVING AVG(`salary`) > 1000
De bovenste query zorgt ervoor dat in het gemiddelde salaris alleen salarissen van hoger dan 1000 euro worden meegeteld. De onderste zorgt ervoor dat alleen groepen met een gemiddeld salaris hoger dan 1000 worden weergegeven.
CASE
Een CASE statement is een hele lange functie die een waarde in een andere kan veranderen. Je geeft hem iets als input (dit kan een veld, maar ook bijv. een functie zijn), en hij gaat alle vertakkingen tot er één matcht. Hij poept dan de waarde achter de match uit.
Dit noemen we pattern matchen.
SELECT `first_name`, CASE `manager_id`
WHEN 100 THEN 'Steven King'
WHEN 101 THEN 'Nina Kochar'
WHEN 102 THEN 'Lex de Haan'
WHEN 103 THEN 'Alexander Hunold'
WHEN 124 THEN 'Kevin Mourgos'
WHEN 149 THEN 'Eleni Zlotkey'
WHEN 201 THEN 'Micael Hartstein'
WHEN 203 THEN 'Shelley Higgins'
END AS `manager` FROM `employees`;
Types
Een veld/kolom in een database kan verschillende soorten data bevatten. Wat voor soort data een kolom bevat staat vantevoren al vast. Het kan niet zo zijn dat rij 1 in een kolom een string (stukje tekst) bevat en rij 2 een datum.
Getallen
INT: een heel getal. KanSIGNED(-128-127) ofUNSIGNED(0-255) zijn.FLOAT: kommagetal met weinig decimalen.DOUBLE: kommagetal met veel decimalen.
Tekst
CHAR: string met een vaste lengte; max 255 chars.TINYTEXT,VARCHAR: string met max 255 chars.TEXT: string met max ~6000 chars.
Data & tijd
DATETIMEDATETIME
Example queries
SELECT
CONCAT(`first_name`, ' ', `last_name`) AS `volledige naam`,
CONCAT('$', `salary`) AS `maandsalaris`,
CONCAT('$', `salary` * 12 + 1.8 * `salary` * 12) AS `jaarsalaris`
FROM `employees`
WHERE
(`first_name` LIKE '%a' OR `last_name` LIKE 'de%')
AND (
(`salary` BETWEEN 4000 AND 7000
AND `bonus` IS null)
OR `salary` > 10000
);
SELECT CONCAT(`first_name`, ' ', `last_name`) AS `personeelslid`, `department_id` AS `afdeling`
FROM `employees`
WHERE MOD(`department_id` / 10, 2) = 0
ORDER BY `afdeling` DESC,
`last_name` ASC;
SELECT CONCAT(SUBSTR(`first_name`, 1, 1), '. ', `last_name`) AS `medewerker`, `hire_date` AS `datum in dienst`
FROM `employees`
WHERE DAY(`hire_date`) = 17
ORDER BY `hire_date`;
SELECT CONCAT('company bv. ', `street_address`, ' ', `postal_code`, ' ', UPPER(`city`), ' ', CASE `country_id`
WHEN 'US' THEN 'United States'
WHEN 'UK' THEN 'United Kingdom'
WHEN 'GER' then 'Germany'
WHEN 'CA' THEN 'Canada'
END) AS `address`
FROM `locations`;
SELECT CASE `department_id`
WHEN 10 THEN 'Administration'
WHEN 20 THEN 'Marketing'
WHEN 50 THEN 'Shipping'
WHEN 60 THEN 'IT'
WHEN 80 THEN 'Sales'
WHEN 90 THEN 'Executive'
WHEN 110 THEN 'Accounting'
WHEN 190 THEN 'Contracting'
ELSE 'Onbekend'
END AS `afdeling`,
CONCAT('$', ROUND(AVG(`salary`), 2)) AS `gemiddeld salaris`,
CONCAT('$', ROUND(SUM(`salary`), 2)) AS `totaal salaris`,
COUNT(`employee_id`) AS `aantal personeelsleden`
FROM `employees`
GROUP BY `department_id`
HAVING `gemiddeld salaris` < 10000 AND `aantal personeelsleden` > 3;
SELECT d.department_name AS `department`, SUM(e.salary) AS `total` FROM employees AS e LEFT JOIN departments AS d ON d.department_id = e.department_id GROUP BY e.department_id
UNION
SELECT d.department_name AS `department`, SUM(e.salary) AS `total` FROM employees AS e RIGHT JOIN departments AS d ON d.department_id = e.department_id GROUP BY e.department_id;
SELECT CONCAT(e.first_name, " ", e.last_name) AS `name`, CONCAT(l.street_address, ' ', l.postal_code, ' ', l.city, ' ', c.country_name) AS `locations` FROM `employees` AS e, `departments` AS d, `locations` AS l, `countries` AS c WHERE e.department_id = d.department_id AND d.location_id = l.location_id AND l.country_id = c.country_id;
SELECT CONCAT(e.first_name, " ", e.last_name) AS `name`, CONCAT(l.street_address, ' ', l.postal_code, ' ', l.city, ' ', c.country_name) AS `locations`
FROM `employees` AS e
JOIN `departments` AS d ON e.department_id = d.department_id
JOIN `locations` AS l ON d.location_id = l.location_id
JOIN `countries` AS c ON l.country_id = c.country_id;
SELECT
CONCAT(SUBSTRING(e.first_name, 1, 1), ". ", e.last_name) AS name,
j.job_title AS title,
h.start_date,
h.end_date,
CONCAT(l.street_address, ' ', l.postal_code, ' ', l.city, ' ', c.country_name) AS location
FROM `employees` AS e
RIGHT JOIN `job_history` AS h ON e.employee_id = h.employee_id
JOIN `jobs` AS j ON h.job_id = j.job_id
-- use h.department_id, because we want the historical location
JOIN `departments` AS d ON h.department_id = d.department_id
JOIN `locations` AS l ON d.location_id = l.location_id
JOIN `countries` AS c ON l.country_id = c.country_id
UNION
(SELECT
CONCAT(SUBSTRING(e.first_name, 1, 1), ". ", e.last_name) AS name,
j.job_title AS title,
-- this selects the end date of the last job (which is the start date of the current one)
DATE_ADD(MAX(h.end_date), INTERVAL 1 DAY),
CURRENT_DATE() as end_date,
CONCAT(l.street_address, ' ', l.postal_code, ' ', l.city, ' ', c.country_name) AS location
FROM `employees` AS e
JOIN `job_history` AS h ON e.employee_id = h.employee_id
JOIN `jobs` AS j ON h.job_id = j.job_id
-- use e.department_id, because we want the current location
JOIN `departments` AS d ON e.department_id = d.department_id
JOIN `locations` AS l ON d.location_id = l.location_id
JOIN `countries` AS c ON l.country_id = c.country_id
GROUP BY e.employee_id
ORDER BY start_date);